

Want to close more deals, faster?
Get Pod!
Fill the form and book your demo today.
Thank you for subscribing!
Oops! Something went wrong. Please refresh the page & try again.

Stay looped in about sales tips, tech, and enablement that help sellers convert more and become top performers.
.png)
The reality is simple. Many do not.
When CRM data is incomplete, outdated, or inaccurate, every downstream decision suffers. Forecasts become guesses. Coaching becomes reactive. Marketing attribution breaks. Leadership loses confidence in the numbers.
This is not just a data hygiene issue. It is a revenue problem.
Here are the most common reasons AE CRM data is dirty and what it is quietly costing you.
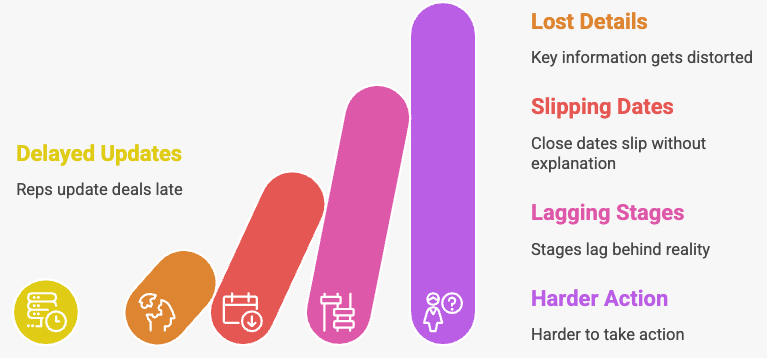
CRM data is only as good as its timing.
When reps update deals hours or days after interactions, key details get lost or distorted. Close dates slip without explanation. Stages lag behind reality.
This delay creates a version of the pipeline that reflects what happened, not what is happening. That gap makes it harder to take action when it matters most.
Close dates often become aspirational instead of factual.
Some reps pull deals forward to hit targets. Others push them out to avoid scrutiny. The result is a pipeline filled with dates that do not reflect actual buyer behavior.
This distorts forecast accuracy and makes it harder to trust any projection tied to those dates.
Stage progression should reflect real buyer progress.
Instead, many deals move forward based on rep optimism rather than objective criteria. This is how stage inflation happens.
When every deal looks like it is in late stages, it becomes impossible to separate real opportunities from weak ones. Using structured frameworks like AI framework analysis tools can help enforce consistent stage definitions and reduce subjectivity.
If fields are not enforced, they do not get filled.
Critical data points like next steps, decision criteria, or stakeholder roles are often missing. This creates blind spots across the pipeline.
With tools like custom AI agent builders, teams can automatically flag missing data and even populate fields based on real activity, reducing the reliance on manual updates.
People change roles constantly.
If your CRM is not actively maintained, you end up with outdated titles, missing stakeholders, and duplicate records. This makes it harder to understand who is actually involved in a deal.
Poor contact data leads to missed relationships, weak multi-threading, and lower win rates.
Some reps log everything. Others log nothing.
This inconsistency creates unreliable data. If activity is not captured uniformly, you cannot accurately measure engagement or deal momentum.
It also weakens any analytics or AI systems that depend on that data to generate insights.
Deal context is often scattered across tools.
Emails live in inboxes. Meeting notes sit in documents. Call recordings are stored elsewhere. The CRM ends up with only fragments of the full story.
Solutions like pipeline coaches bring these signals together into a single view, making it easier to understand what is actually happening inside each deal.
Every pipeline has them. Deals that look active but are effectively dead.
These “zombie deals” inflate pipeline coverage and create a false sense of security. They also distract reps from focusing on real opportunities.
Using prioritization tools helps identify which deals are actually worth attention and which should be removed.
Attribution data is often treated as an afterthought.
But when lead source fields are inconsistent or incorrect, marketing decisions suffer. Budget gets allocated based on flawed assumptions.
This is not just a sales issue. It directly impacts how revenue teams invest in growth.
This is the root cause behind many of these issues.
When the CRM feels like an administrative burden instead of a helpful tool, reps do the minimum required or avoid it altogether.
If the system does not give value back to the rep, data quality will always degrade over time.
When the underlying data is flawed, forecasting becomes an exercise in optimism.
Stage-based models rely on assumptions that break when stages are inaccurate. Close dates cannot be trusted. Engagement signals are incomplete.
Signal-based approaches use real activity and deal behavior to produce more reliable forecasts, reducing dependence on guesswork.
Dirty CRM data does not just affect reporting. It affects every part of your revenue engine.
It impacts how reps prioritize their time, how leaders forecast performance, and how teams invest in growth.
Solving it requires more than stricter rules. It requires systems that automatically capture, validate, and enrich data without adding friction for reps.
If you want a clearer, more reliable view of your pipeline, explore our AI agent builder or see how Pod supports RevOps teams here.
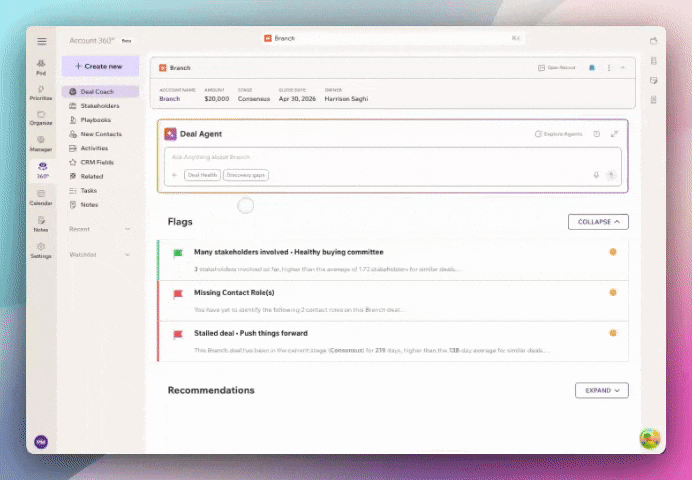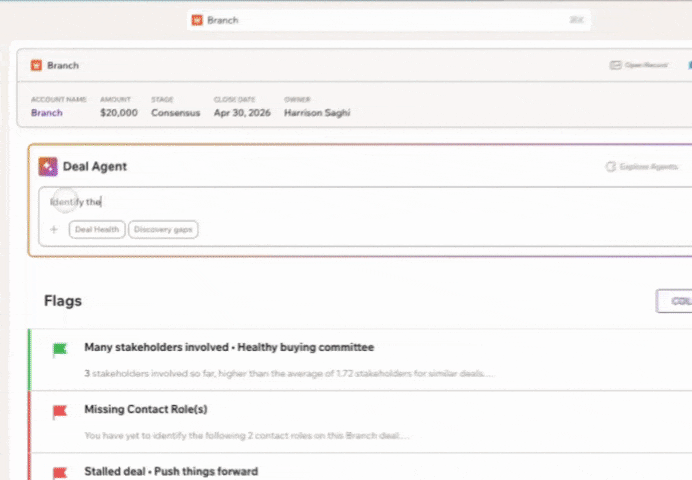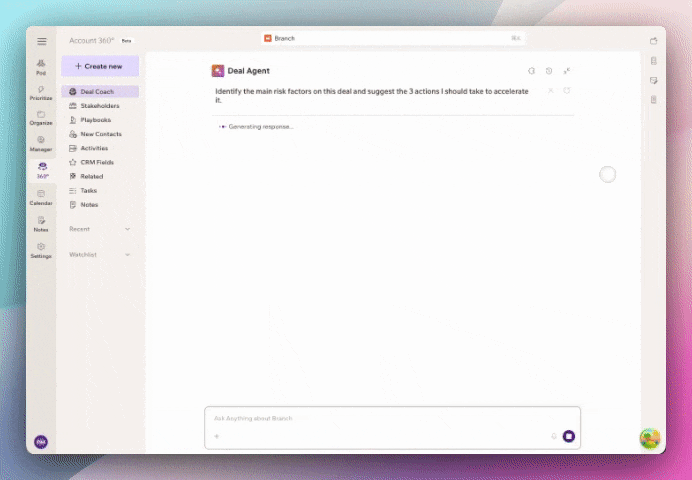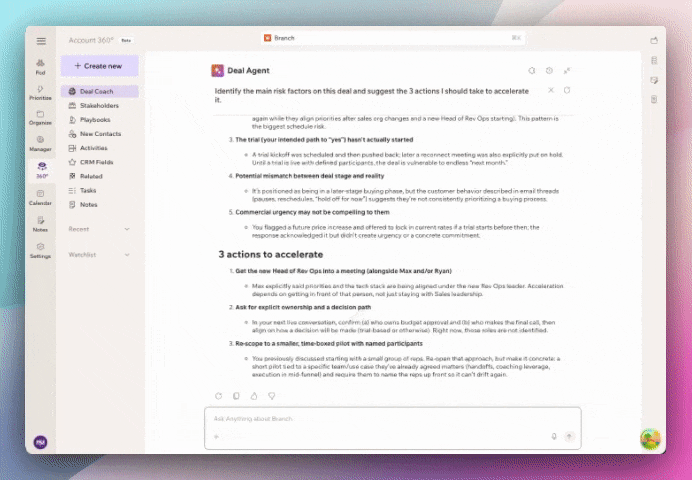
Because when your data is clean, your decisions get sharper. And that shows up directly in revenue. Book a demo today.

















